
事業規模が拡大し、大規模なデータの管理が必要になるにつれて、SnowFlake や BigQuery のようなハイパワーな DWH サービスでデータを加工するケースは多いです。
その際、想定外な高額請求が起こる原因のひとつに、クエリが最適化されておらずスキャン量が増大しているケースがあります。
そのため、クエリのスキャン量を監視・管理することが課金額を減らすうえで有効な手段となることがあります。
本記事では、前半で BigQuery で課金されるスキャン量を監視・管理するまでのプロセスを振り返り、 後半で BigQuery の課金額を減らすために簡単にチェックできることについてお話しします。
BigQuery クエリにおけるスキャン量を監視・管理するに至った理由
BigQuery の課金額が想定より大幅に増加していた
データスキャン量が明らかに大きいクエリが実行されたときにニアリアルタイムで感知できるシステムを作りたかった
- クエリを見直してスキャン量を削減し、定期的なクエリ管理を行える環境を作りたかった
Monitoring アラートによる Slack 通知の設定
まず、ニアリアルタイムでデータスキャン量を監視するために、Monitoring アラートを Slack と連携させて通知させる仕組みを作るようにしました。
以前は Slack 通知を設定するためには Webhook を利用するのが一般的でしたが、現在は Cloud Monitoring の GUI 画面上で直感的に柔軟なアラートを作成できます。
(※ ただし、IAM で Monitoring 編集者のロールが付与されている必要があります)
Monitoring→アラートから管理したい指標と閾値を設定して通知ポリシーを作成し、それを特定の Slack チャンネルに紐付けておくことで、閾値を超えたときに自動で通知がいく仕組みです。
Monitoring アラートの接続先は Slack だけでなく GoogleChat、メール、WebHook、Pub/Sub など幅広く対応しているため柔軟な使い方が可能です。
今回は「クエリで課金されたスキャン量」を見たいので、指標設定を Statement scanned bytes billed として、プロジェクト内のクエリ課金バイト数を測定するようにしました。
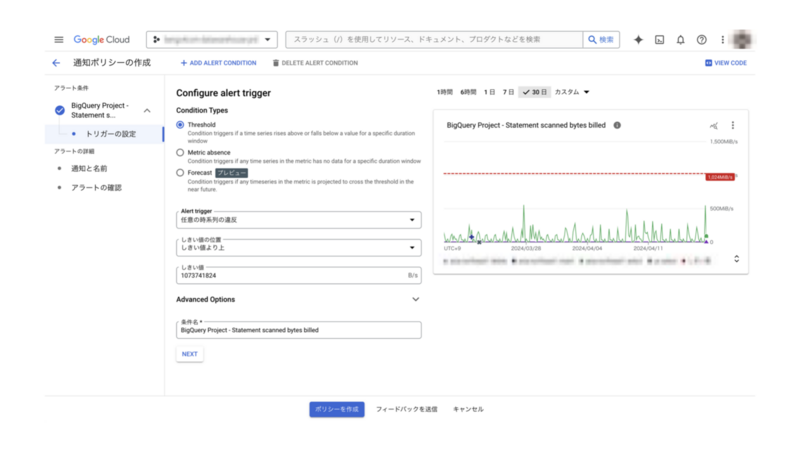
Looker Studioでの可視化
しかし、この通知方式にはデメリットもあります。
時間単位の集計であり、ジョブ単位ではない
ジョブの詳細な情報を表示できない
このアラートはあくまでジョブ単位ではなく指定期間内のサンプリングを参照するため、長時間稼働したジョブを検知できない場合や、短期間に多くのジョブを実行したことで通知される場合があります。
このようにクエリを直接参照できるわけではないので、クエリごとに課題点を探るには不向きでした。
できることならジョブごとに管理・集計ができる環境も整えたかったのです。
そこで、Looker Studio を利用した可視化の仕組みを検討しました。 INFORMATION_SCHEMA ビューから取得したデータを Looker Studio に接続することで、ジョブを柔軟に可視化できます。
以下のようにクエリビューを作成して、各ジョブのサイズやスロット量、参照データセットに加えて改善点を振り替えられるようにジョブのクエリも出力できるようにします。
/* Looker Studioに渡すジョブのメタデータビュー */ SELECT job_id, SAFE_CAST(ROUND(SUM(total_bytes_billed / 1073741824), 3) AS numeric) AS size_gb, -- 読み込まれるバイト量[GB] MAX(total_slot_ms)/1000 AS total_slot_sec, -- 使われたスロット量[秒] MAX(creation_time) AS creation_time, ARRAY_AGG(destination_table) AS destination_table, -- ジョブの実行場所 ARRAY_AGG(ref_t) AS reference, -- クエリの参照先 MAX(user_email) AS email, -- サービスアカウント別に分ける MAX(query) AS query FROM `sample-project-id`.`region-location`.INFORMATION_SCHEMA.JOBS, UNNEST(referenced_tables) AS ref_t WHERE DATE(creation_time, 'Asia/Tokyo') BETWEEN DATE(TIMESTAMP_SUB(CURRENT_TIMESTAMP(), INTERVAL 14 DAY)) AND DATE(CURRENT_TIMESTAMP()) -- 過去2週間分出力 AND total_bytes_billed >= 107374182400 -- 100GB以上のジョブに限定 GROUP BY job_id
このビューを Looker Studio に接続し、ジョブ単位でサイズの大きいクエリやスロットを多く使うクエリを絞り込めるようにダッシュボードを作成します。
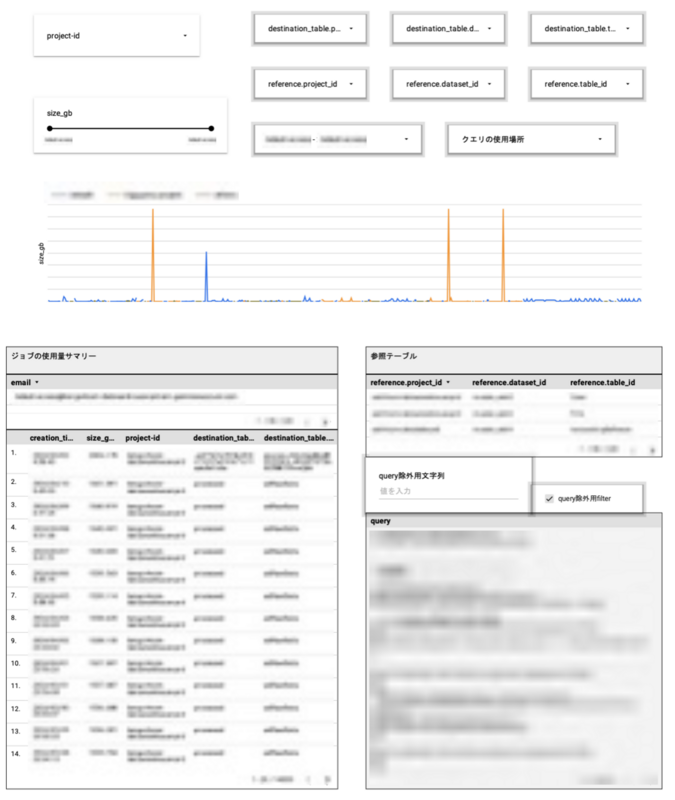
これで、見直したほうが良いクエリをジョブ単位で特定できるようになり、改善すべき点を探りやすくなりました。
課金額抑制に効果的なベストプラクティス
BigQuery の料金システムは多岐に渡りますが、特に重要なものは以下の 2 つです。
- 保存しているデータ量に応じたストレージ料金
- スキャン量に応じたコンピューティング料金
そこで、このセクションではストレージとコンピューティングについてそれぞれチェックするべき点をいくつかご紹介します。
ストレージを減らすために
1. テーブルの有効期間を設定する
各テーブルには有効期間を設定できます。
一時的なテーブルを自動で削除するように設定しておくことで、前任者の退職やプロジェクトの凍結などで不必要になったデータテーブルが山積する事態を防げます。
2. 東京 (asia-northeast1) ロケーションを使わない
実は、ストレージ料金はデータが格納されたロケーションによって異なります(最新の情報は公式ページを確認してください)。
テーブルの種類や使用状況によって料金は異なりますが、総じて US や EU よりも東京 (asia-northeast1) の方が割高になります。
そのため、US や EU でデータセットを作成すると価格を抑えられます。
なおロケーションはテーブル作成後に変更できませんので注意してください。
ただし、ロケーションは自社のリーガルの要件を確かめた上で設定する必要があるので、事前に問題がないか確認しておきましょう。*1
3. Cloud Storageの使用を検討する
長期にわたってデータを保存する場合で、かつ変更をほとんど行わないテーブルは BigQuery ストレージではなく Cloud Storage に保存するほうが費用を抑えられることがあります。
Cloud Storage はデータを変更しない期間を長くするほど安くなる課金システムになっています。
2024 年 4 月現在の BigQuery ストレージと Cloud Storage の課金額は以下のとおりです。
BigQuery
| 論理テーブル(アクティブ) | 論理テーブル(長期) | 物理テーブル(アクティブ) | 物理テーブル(長期) | |
|---|---|---|---|---|
| US(us) | $0.02 / GiB | $0.01 / GiB | $0.04 / GiB | $0.02 / GiB |
| Europe(eu) | $0.02 / GiB | $0.01/GiB | 使用不可 | 使用不可 |
| 東京(asia-northeast1) | $0.023 / GiB | $0.016 / GiB | $0.052 / GiB | $0.026 / GiB |
※毎月 10GiB の無料枠が用意されます。
※ 10 MB 以下は切り上げられます。
※ 90 日間参照・編集されていないテーブルが長期保存として扱われます。
Cloud Storage
| Standard (最小保存期間なし) | Nearline (最小保存期間 30 日) | Coldline (最小保存期間 90 日) | Archive (最小保存期間 365 日) | |
|---|---|---|---|---|
| US(us) | $0.026 / GB | $0.015 / GB | $0.007 / GB | $0.0024 / GB |
| Europe(eu) | $0.026 / GB | $0.015 / GB | $0.007 / GB | $0.0024 / GB |
| 東京(asia-northeast1) | $0.023/GB | $0.016 / GB | $0.006/GB | $0.0025 / GB |
ただし、Cloud Storage は API の呼び出しによっても課金されます。
そのため、更新頻度が高く多量のファイルを送受信する場合はむしろ高額になることがあるので、注意して運用する必要があります(ただし、同じロケーション内での BigQuery データ転送は課金対象外です)。
API ごとの課金額は公式ページに詳細が掲載されています。
4. パーティショニングとクラスタリング
パーティショニングを行うと呼び出されるテーブルが限定されることになるため、使用されなかったパーティションテーブルが長期テーブルとなり、結果的に費用を抑えられる可能性があります。
スキャン量を減らすために
1. SELECT *を使わない
BigQuery はカラム型データ構造であり、列ごとに処理が走ります。
そのため、列の参照が限定されるほど価格は安くなります。
使用しない列が存在するにもかかわらずワイルドカードを用いるとそれだけ余計なスキャンが発生し、課金額が上がる要因となります。
またWHERE句中で条件指定用に列を指定したときも同様に指定列へのスキャンが発生します。
なおWITH句によるサブクエリや、LIMIT句を用いたとしてもスキャン量は変化しないので、課金額の抑制には使えません。
2. サブクエリの条件指定漏れ
WITH句などを用いて複数のサブクエリを 1 つのクエリ上に記述していると、全体では日時などで条件指定をしているにもかかわらず、特定のサブクエリには条件指定をつけ忘れていることがあります。
この場合、サブクエリ内で発生する読み込みでは不要な範囲までスキャンが発生し、クエリ全体のスキャン量が爆発的に増大するということが起こりえます。
BigQuery コンソール上で行っている場合は Dry Run によって気付けますが、パイプラインツールを用いてクエリを記述した場合はスキャン量が多いことに気付かないままでいることがあります。
3. 課金データ量の上限設定
各クエリには課金データ量の上限を設定できます。
個人的に使用する分には問題ないのですが、複数人が同じクエリを使用する場合は呼び出し回数によって膨大な課金額になる可能性があります。事前に上限を設定しておくことで、そのような状況を事前に防げます。
4. 連続的なフィールドに対してパーティションとクラスタリングを使用する
パーティションとクラスタリングを使用することで、呼び出すテーブルの範囲を限定させられます。
スキャン量を減らすことができるほか、パフォーマンスの向上にも繋がり、ストレージ料金の改善にもつながるので積極的に取り入れたほうがよいでしょう。
まとめ
今回は BigQuery ジョブの管理とコスト削減に焦点を当てて、お話をさせていただきました。
このプロセスによって減少できた課金額を具体的に書くことはできませんが、クエリの最適化で大幅にスキャン量を減らせる事例をいくつか発見できました。
またあらかじめコストについて意識を共有し、データ管理の重要性を理解していただくことで、データガバナンスの体制をスムーズに作れるという利点もあると考えています。
ご読了いただきまして、ありがとうございました。
*1:コメントでいただいた意見を元に追記させていただきました。