
この記事は、弁護士ドットコム Advent Calendar 2025 の 1 日目の記事です。
はじめに
こんにちは。契約マネジメントプラットフォームのクラウドサインの開発に携わっている神達です。 開発の中でコードの依存関係を整理し、可読性・保守性・拡張性を意識した疎結合な実装に取り組んだ内容を共有します。 1 つの実践例として参考にしていただければ幸いです。
結論
この記事では CSV ファイルの入力値を検証するコードを疎結合にする過程と考え方について記載しています。
- CSV ファイルに大量の項目が含まれていると検証処理が複雑化しやすい
- 依存関係のある検証ロジックが大きくなると可読性・保守性・拡張性が下がる
- 責務を明確にして interface に依存させることで改善できる
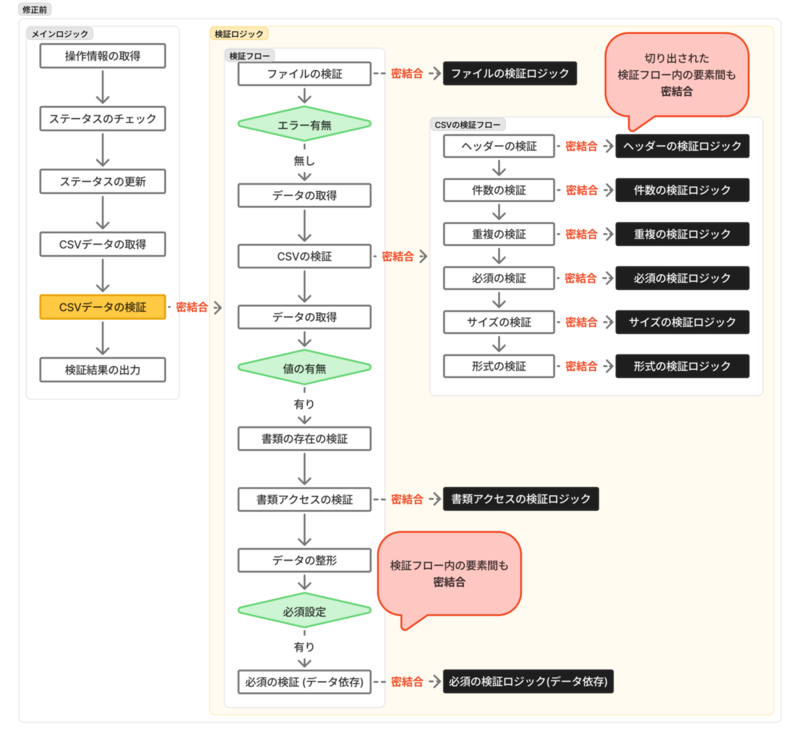
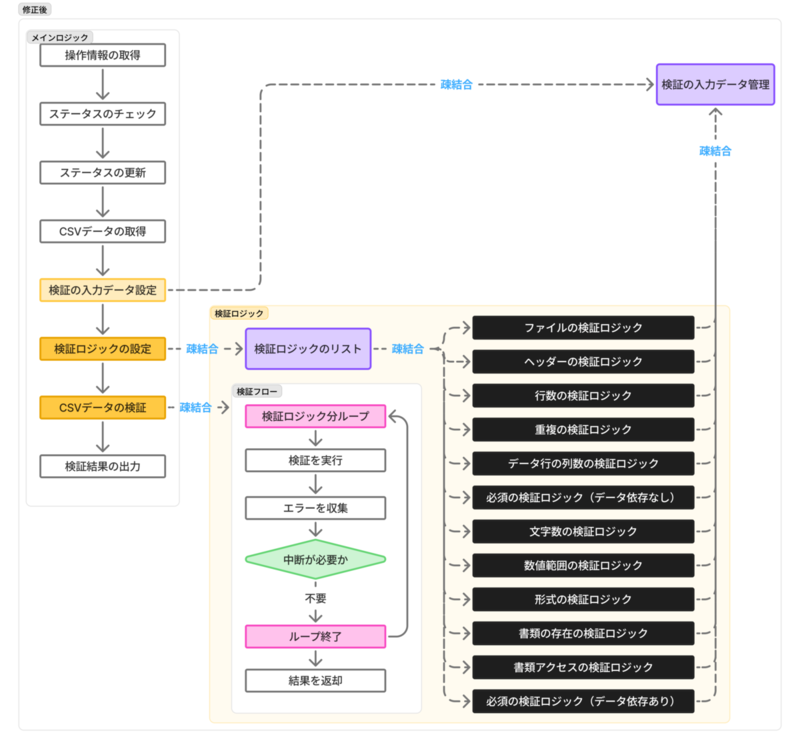
修正前後の構成図は以下のとおりです。上が修正前で下が修正後です。
今回の要件と仕様
要件
今回求められている要件は以下のとおりです。
- ユーザーが複数の書類データを一括で更新したい
- 更新で指定する値に問題があれば、どの値にどんな問題があるのか明確に検知したい
- できるだけ少ない手数で指定する値を修正して更新したい
- 項目の一部はユーザー側の設定で独自に作りたい
- 項目ごとに必須入力か任意入力かを柔軟に制御したい
仕様
今回の要件を満たすための仕様は以下のとおりです。
- ユーザーは CSV ファイルをアップロードすることで更新用の値をまとめて指定可能
- CSV ファイルには多数の列と行が存在している(最大 30 列 × 2000 行を想定)
- 指定された値について必須・形式・範囲・整合性といった内容を検証する
- 指定された値に問題があった場合、行数・項目名・問題の内容を出力する
- 複数の問題が存在する場合、可能な限りまとめて出力する
- オプション項目や必須設定に応じてヘッダーおよび値を動的に検証する
最初の状態
まずは、あまり設計を意識せずに「とりあえず仕様を満たす」ように実装してみた状態を例示します。 なお今回の趣旨にあまり関係しない部分は簡略化しているのでご了承ください。
メインロジック
呼び出し元のメインロジックのサンプルです。
コード(記載量が多いので折りたたみ可能にしています)
func (u *usecase) run(manipulationID string) error { // 操作情報の取得 manipulation, err := u.repository.Manipulation(manipulationID) if err != nil { return err } if manipulation == nil { return err } if manipulation.Status != uploaded { return errors.New("invalid status") } manipulation.Status = checking if err := u.repository.Update(manipulation); err != nil { return err } // CSVデータの取得 csvData, err := manipulation.ReadFile() if err != nil { return err } // ☆☆☆ 今回の主役の検証処理 ☆☆☆ checkErrors, err := u.check(csvData, manipulation) if err != nil { return err } // 結果の出力 if err := u.outputResult(checkErrors, manipulation); err != nil { return err } return nil }
検証ロジック
呼び出し元
いくつか処理を切り出していますが、それらの呼び出しを含む検証全体のロジックが以下のとおりです。 量が多いので詳細は理解せずとも雰囲気だけ感じて貰えればいったん大丈夫です。
コード(記載量が多いので折りたたみ可能にしています)
func (u *usecase) check(csvData []byte, manipulation Manipulation) ([]CheckError, error) { // NOTE: checkErrors に今後の検証エラーを追加していく // ファイルの検証 checkErrors := validateFile(csvData) // ファイルのエラーがある場合は以降の検証をスキップ if len(checkErrors) > 0 { return checkErrors, nil } // CSV データを slice に変換 csvReader := csv.NewReader(bytes.NewReader(csvData)) csvRows, err := csvReader.ReadAll() if err != nil { return nil, err } // レコードが0件の場合は以降の検証をスキップ if len(csvRows) == 0 { checkErrors = append(checkErrors, CheckError{Message: "レコードが0件です"}) return checkErrors, nil } // オプション項目の取得 options, err := u.repository.Options() if err != nil { return nil, err } // 必須設定の取得 required, err := u.repository.Required() if err != nil { return nil, err } // 期待するヘッダーを取得 expectedHeaders := u.generateHeader(required, options) // CSV としての検証 checkErrors = append(checkErrors, validateCSV(csvRows, expectedHeaders)...) // 書類IDのリスト、行番号のマップを生成 docIDs := make([]string, 0, len(csvRows)-1) rowNumMap := make(map[string]int, len(csvRows)) for i, row := range csvRows { if i == 0 { // ヘッダー行はスキップ continue } docID := row[ColIndexDocumentID] docIDs = append(docIDs, docID) if _, exists := rowNumMap[docID]; exists { continue } rowNumMap[docID] = displayRowNumber(i) } // 書類IDが存在しない場合は以降の検証をスキップ if len(docIDs) == 0 { return checkErrors, nil } // 登録されている書類を取得 docs, err := u.repository.Documents(docIDs) if err != nil { return nil, err } // 書類が存在するかの検証(取得できたデータと比較) checkErrors = append(checkErrors, verifyDocumentExistence(docs, rowNumMap)...) // 書類にアクセス可能かの検証 va := verifyAccessible{ logger: u.logger, repository: u.repository, docs: docs, rowNumMap: rowNumMap, } accessibleDocs, cErrors, err := va.verify() if err != nil { return nil, err } checkErrors = append(checkErrors, cErrors...) // アクセス可能な書類IDのマップを生成 accessibleDocIDMap := make(map[string]struct{}, len(accessibleDocs)) for _, doc := range accessibleDocs { accessibleDocIDMap[doc.ID] = struct{}{} } // アクセス可能な書類に対応する CSV 行のみ抽出 accessibleCSVRows := make([][]string, 0, len(accessibleDocs)) for i, row := range csvRows { if displayRowNumber(i) != rowNumMap[row[ColIndexDocumentID]] { continue } if _, exists := accessibleDocIDMap[row[ColIndexDocumentID]]; exists { accessibleCSVRows = append(accessibleCSVRows, row) } } // 必須設定が存在する場合は、必須条件を満たしているか検証 if required != nil { checkErrors = append(checkErrors, verifyRequired(accessibleCSVRows, required, rowNumMap)...) } return checkErrors, nil }
切り出された検証
上述の check メソッドから呼び出される検証処理のサンプルです。
イメージを掴んでもらうためのものなので一部だけ載せています。
量が多いので詳細は理解せずとも雰囲気だけ感じて貰えればいったん大丈夫です。
コード(記載量が多いので折りたたんでます)
// ファイルの検証 func validateFile(data []byte) []CheckError { var errors []CheckError // ファイルサイズが0の場合 if len(data) == 0 { errors = append(errors, CheckError{Message: "ファイルが空です"}) } // ファイルサイズが上限を超えている場合 if len(data) > MaxFileSize { errors = append(errors, CheckError{Message: "ファイルサイズが上限を超えています"}) } // 以降省略 return errors } // ファイルに含まれる CSV データの検証 func validateCSV(rows [][]string, expectedHeaders []string) []CheckError { var errors []CheckError // ヘッダー行の検証 headerErrors := validateHeader(rows, expectedHeaders) errors = append(errors, headerErrors...) // ヘッダー行に問題があれば以降の検証をスキップ if len(headerErrors) > 0 { return errors } // 件数チェック dataRowCount := len(rows) - 1 // ヘッダー行を除く if dataRowCount == 0 { errors = append(errors, CheckError{Message: "編集対象のデータが指定されていません"}) // データ行がない場合は以降の検証をスキップ return errors } if dataRowCount > EditMaxRecords { errors = append(errors, CheckError{Message: fmt.Sprintf("処理上限件数(%d行)を超えています", EditMaxRecords)}) } // 行の重複を検証 duplicatedRows, duplicationErrs := validateDuplication(rows) errors = append(errors, duplicationErrs...) for i, row := range rows { // ヘッダー行はスキップ if i == 0 { continue } // 重複行はスキップ if _, isDuplicated := duplicatedRows[i]; isDuplicated { continue } dispRowNum := displayRowNumber(i) // 列数が期待値と異なる場合は早期にエラーを登録しスキップ if len(row) != len(expectedHeaders) { errors = append(errors, CheckError{ RowNumber: dispRowNum, Message: "列数が正しくありません", }) continue } errors = append(errors, validateRequired(dispRowNum, row)...) errors = append(errors, validateSize(dispRowNum, row, expectedHeaders)...) errors = append(errors, validateFormat(dispRowNum, row)...) } return errors } // 行の重複を検証 func validateDuplication(rows [][]string) (map[int]string, []CheckError) { var errors []CheckError rowDuplicatesMap := make(map[int]string) // キーが書類ID、値がヘッダー行を考慮した表示用の行番号のマップを作成 docIDs := make(map[string]int) for i, row := range rows { // ヘッダー行はスキップ if i == 0 { continue } // 列が足りない場合はスキップ if len(row) <= int(ColIndexDocumentID) { continue } // 書類IDが空の場合はスキップ docID := row[ColIndexDocumentID] if docID == "" { continue } rowNum, exists := docIDs[docID] // 重複していない場合はマップに追加 if !exists { docIDs[docID] = displayRowNumber(i) continue } rowDuplicatesMap[i] = docID var docTitle string if len(row) > int(ColIndexDocumentTitle) { docTitle = row[ColIndexDocumentTitle] } errors = append(errors, CheckError{ RowNumber: displayRowNumber(i), DocumentID: docID, DocumentTitle: docTitle, Message: fmt.Sprintf("書類IDが%d行目と重複しています", rowNum), }) } return rowDuplicatesMap, errors } // 他の validate や verify の関数は省略
問題点
最初の状態に存在する問題を洗い出してみます。
メインロジックから検証ロジックへの依存
メインロジック(run メソッド)から検証ロジック(check メソッド)へ強く依存してしまっています。
この状態だとメインロジックのテストコードを書くときに検証ロジック内の制御を意識する必要があり、ロジックが大きくなると複雑化しやすくなります。
また検証ロジックの変更がメインロジックのテストコードにも波及します。
検証ロジック間の依存
検証ロジック(check メソッド)内の処理が互いに依存し合っている状態です。
例)
- 切り出してある検証処理は単純に関数・メソッドになっているだけのため、検証全体のテストコードを書く際に呼び出されている各検証ロジック内の制御を意識する必要がある
- ファイルの検証(
validateFile関数)より後の検証は、ファイルの検証に問題があるかどうかで実行有無が変わる - 重複の検証(
validateDuplication関数)の結果がそれ以降の検証処理を行うかの分岐条件に使われている - 書類にアクセス可能かの検証(
verifyAccessible.verifyメソッド)の結果がそれ以降の検証の入力として使われている - 切り出されず単純な分岐になっているが内容としては検証のものもあり、前後のデータ取得や検証と関連する形で実装されている
この状態だと検証ロジック(check メソッド)のテストコードを書くときに検証処理間の依存関係を強く意識する必要があり、ロジックが大きくなると複雑化しやすくなります。
1 つのコードでさまざまな処理に対してモックを多用することになり、モックを読み解いて設定するだけでかなりの労力になります。
また一部の検証ロジックを修正する際に他の検証ロジックへの影響を考慮する難易度が非常に高くなります。
目的の違う処理の混在
検証ロジック・入力データの整形・処理順序の指定・処理中断の分岐、といった目的の異なる処理が 1 つの処理にまとまって記述されています。 また検証ロジックの分割についても同じ粒度で行われておらず、機能を追加する際にどこへ何を書くと良いか分かりにくくなっています。 複数の目的の処理が混ざって依存している状態だと、それを読み解いて修正または拡張する難易度が高くなります。
検証ロジックにおける CSV の形式への依存
検証ロジックが CSV の形式へかなり依存した実装になっています。
例)
- ヘッダー行が 1 行目、それ以降がデータ行
- 取得したい項目に対応する列番号
- 列の存在チェック
- slice の index に対応する行番号
これらが検証ロジックに露出した状態だと、一番集中したい検証以外の制御実装が増えて複雑になってしまいます。 可読性が下がるだけでなく、これらの制御に修正を加えた際の横展開のコストが大きくなります。 また値の取得に際してエスケープやホワイトスペースの削除などを行いたい場合にも各検証ロジックでの変更が発生してしまいます。
問題の背景
問題の背景を分析してみます。
- 実装の規模と複雑度で求められる分割や依存関係の管理の程度は変わる
- 小規模またはシンプルであれば依存があっても問題が顕在化しにくい
- 項目の数や内容が動的に変わるため、 CSV の値を構造体の明示的なフィールドなどにマッピング出来ない
- 扱いにくい形式ゆえに複雑性が発生している
- 最終形が分からない状態で書き始めたために全体を俯瞰した最適化が出来なかった
- 多数の複雑な制御が入るコードは、書ききってみるまで最終形が見通せないことも多々ある
経験値を積んで早い段階で見通す能力を上げるのが理想ですが、難しければ今回のようにある程度実装してからリファクタリングでも良さそうです。
改善方針
ここまで挙げた問題点とその背景を踏まえて、どのようにリファクタリングしていくかの方針を整理します。
メインロジックと検証ロジックの依存を弱める
- 検証ロジック(
checkメソッド)を専用の interface・構造体・メソッドに切り出す - メインロジックの構造体のフィールドに対して、 interface の型で検証ロジックの DI(依存性の注入)を行う
- メインロジックの処理の中で DI した検証ロジックを実行する
こうすることで依存性が逆転され、メインロジックから検証ロジックの詳細へ依存しなくなります。 そうするとテストコードは検証ロジックと同じ interface を実装したモックへ差し替え可能になります。 モックによりテストコードの記述がシンプルになり、 検証ロジックの実装の変更がメインロジックのテストコードへ波及しない状態にできます。
検証ロジックの分離
- 各検証ロジックを共通の interface を実装した専用の構造体・メソッドに切り出す
- 検証全体の呼び出し元で各検証ロジックの実行有無・順序・中断の必要を指定する
- 検証全体の呼び出し元で、指定された検証ロジックのリストをループして順序通り実行する
こうすることで検証ロジック同士の依存関係を無くし、検証全体の制御についても順序と中断有無だけに集中出来ます。 テストコードについても呼び出し元がテストすべき範囲は指定した検証ロジックの実行・順序・中断が期待通りになるかだけで、個別の検証の詳細については関心を持たなくて済みます。 また検証ロジックを修正する場合は各構造体・メソッドの範囲だけで済み、保守性が向上します。 検証ロジックを追加する場合も interface さえ実装していれば、既存の検証ロジックの詳細を意識する必要がありません。
入力データの分離
- 検証ロジック全体で使う入力データを保持・取得できる専用の interface・構造体・メソッドを定義する
- データの種類ごとに保持するための構造体のフィールドや取得用メソッドを定義する
- CSV などの扱いにくいデータは専用の構造体でラップしたり、専用の取得メソッドで扱いをカプセル化する
- 各検証ロジックからこの処理を経由してデータ取得するように変更する
こうすることで検証ロジックの入力となる値に関する制御を切り出し、検証ロジックでシンプルに扱えるようになります。 取得した値を保持しておくことで、複数回取得される場合もキャッシュして使い回す事ができます。 DB や外部ストレージなど取得コストが発生する場合に呼び出し数が増えても 1 度のコストで済むようになります。
改善後
方針どおりに改善したサンプルです。
メインロジック
検証の入力値管理の生成と検証処理が DI されたうえで処理の中で実行されています。
コード(記載量が多いので折りたたんでます)
type usecase struct { checkerParamBase CheckerParamBase // interface checker ChainChecker // interface // その他のフィールドは省略 } func NewUsecase(repository Repository, logger *slog.Logger) *usecase { return &usecase{ checkerParamBase: NewCheckerParamBase(repository), checker: NewChainChecker(logger), // その他のフィールドは省略 } } func (u *usecase) run(manipulationID string) error { // 操作情報の取得 manipulation, err := u.repository.Manipulation(manipulationID) if err != nil { return err } if manipulation == nil { return err } if manipulation.Status != uploaded { return errors.New("invalid status") } manipulation.Status = checking if err := u.repository.Update(manipulation); err != nil { return err } // CSVデータの取得 csvData, err := manipulation.ReadFile() if err != nil { return err } // ☆☆☆ 検証の入力値管理のインスタンスを生成して、検証のインスタンスに設定 ☆☆☆ checkerParam := u.checkerParamBase.NewCheckerParam(manipulation, csvData) err = u.checker.SetCheckers(checkerParam) if err != nil { return err } // ☆☆☆ 検証 ☆☆☆ checkErrors, err := u.checker.Execute() if err != nil { return err } // 結果の出力 if err := u.outputter.Execute(checkErrors, manipulation); err != nil { return err } return nil }
すべて例示するとボリュームが非常に大きくなるので最小限のサンプルですが、モックを使って自身のロジックのみを意識したテストコードになっています。
コード(記載量が多いので折りたたんでます)
// MockChecker は checker のモック type MockChecker struct { ExecuteFunc func() ([]CheckError, error) } func (m *MockChecker) SetCheckers(param CheckerParam) error { return nil } func (m *MockChecker) Execute() ([]CheckError, error) { if m.ExecuteFunc != nil { return m.ExecuteFunc() } return nil, nil } // MockOutputter は outputter のモック type MockOutputter struct { ExecuteFunc func(checkErrors []CheckError, manipulation *Manipulation) error } func (m *MockOutputter) Execute(checkErrors []CheckError, manipulation *Manipulation) error { if m.ExecuteFunc != nil { return m.ExecuteFunc(checkErrors, manipulation) } return nil } // 非常に簡略化したメインロジックのテスト(モックの使用例) func TestUsecase_Run(t *testing.T) { assert := assert.New(t) require := require.New(t) // 検証処理のモックから返され、出力処理のモックで受け取ることを期待する値 expectedErrors := []CheckError{ {RowNumber: 1, ColumnName: "テスト項目", Message: "必須項目です"}, } // 検証処理のモック mockChecker := &MockChecker{ ExecuteFunc: func() ([]CheckError, error) { return expectedErrors, nil // モックの戻り値 }, } // 出力処理のモック var receivedCheckErrors []CheckError mockOutputter := &MockOutputter{ ExecuteFunc: func(checkErrors []CheckError, manipulation *Manipulation) error { receivedCheckErrors = checkErrors // 引数で受け取った値をテスト用に保持する return nil }, } usecase := &usecase{ checker: mockChecker, outputter: mockOutputter, } err := usecase.run("test-id") require.NoError(err) // 検証処理のモックから返され、出力処理のモックで受け取った値が期待通りか比較 assert.Equal(expectedErrors, receivedCheckErrors) }
入力値の管理
検証ロジックから入力値の取得のために参照される処理です。 DI する部分をメインロジックから値を渡す部分と分けるために、ベースの interface・構造体・メソッドを別途定義しています。
コード(記載量が多いので折りたたみ可能にしています)
type CheckerParam interface { Manipulation() Manipulation CSVData() []byte CSVRows() ([]CSVRow, error) CSVHeaders() ([]string, error) CSVDataRows() ([]CSVRow, error) CSVDistinctDataRows() ([]CSVRow, error) RowNumberMap() map[string]int DocumentIDs() []string Documents() ([]CSVDocument, error) ExpectedHeaders() ([]string, error) Options() ([]Option, error) Required() (*Required, error) } type CheckerParamBase interface { NewCheckerParam(manipulation Manipulation, csvData []byte) CheckerParam } type checkerParamBase struct { repository Repository } func NewCheckerParamBase(repository Repository) CheckerParamBase { return &checkerParamBase{ repository: repository, } } func (b *checkerParamBase) NewCheckerParam(manipulation Manipulation, csvData []byte) CheckerParam { // 操作情報と CSV データは初期化時にセット return &checkerParam{ manipulation: manipulation, csvData: csvData, base: *b, } } // 構造体のフィールドで値を保持する type checkerParam struct { manipulation Manipulation csvData []byte csvRows []CSVRow csvDistinctRows []CSVRow rowNumberMap map[string]int documentIDs []string csvDocuments []CSVDocument expectedHeaders []string options []Option required *Required base checkerParamBase } // 操作情報を取得する func (p *checkerParam) Manipulation() Manipulation { return p.manipulation } // CSV データを取得する func (p *checkerParam) CSVData() []byte { return p.csvData } // CSV のレコードを取得する func (p *checkerParam) CSVRows() ([]CSVRow, error) { // 既に存在する場合は保持している値を返す if p.csvRows != nil { return p.csvRows, nil } // 初回の取得時は CSV データから読み込んで値を保持してから返す csvReader := csv.NewReader(bytes.NewReader(p.csvData)) csvRows, err := csvReader.ReadAll() if err != nil { return nil, err } p.csvRows = NewCSVRows(csvRows) return p.csvRows, nil } // 以降、 interface のメソッド実装が続くが省略
検証ロジックの全体設定と実行
どの検証処理を実行するか、順序はどうするか、エラー発生時に中断するかを指定する検証全体の制御です。 追加する場合は新たに作った検証ロジックをリストに入れるだけで済みます。 削除する場合もリストから除くだけです。
コード(記載量が多いので折りたたみ可能にしています)
type Checker interface { EnableStopOnError() Checker Check() error HasStop() bool CheckErrors() []CheckError } type ChainChecker interface { SetCheckers(param CheckerParam) error Execute() ([]CheckError, error) } type chainChecker struct { logger *slog.Logger checkers []Checker } func NewChainChecker(logger *slog.Logger) ChainChecker { return &chainChecker{ logger: logger, } } // Checker interface を実装した検証ロジックを設定する func (c *chainChecker) SetCheckers(param CheckerParam) error { // 上から順に実行される c.checkers = []Checker{ // Validate(登録済みデータに依存しない純粋な入力値の検証) NewValidatorFile(param).EnableStopOnError(), // ファイル NewValidateHeader(param).EnableStopOnError(), // ヘッダー NewValidatorRowSize(param).EnableStopOnError(), // 行数 NewValidatorDuplication(param), // 重複 NewValidatorDataRowColSize(param), // データ行の列数 NewValidatorRequired(param), // 必須(データ依存なし) NewValidatorTextLength(param), // 文字数 NewValidatorNumberSize(param), // 数値範囲 NewValidatorFormat(param), // 形式 // Verify(登録済みデータに依存する現在の状態も含めた入力値の検証) NewVerifierDocumentExistence(param), // 書類の存在 NewVerifierAccessible(c.logger, param), // 書類アクセス NewVerifierRequired(param), // 必須(データ依存あり) } return nil } // SetCheckers で設定された Checker を順に実行し、検証エラーを収集する func (c *chainChecker) Execute() ([]CheckError, error) { checkErrors := []CheckError{} for _, checker := range c.checkers { // 検証の実行 err := checker.Check() if err != nil { return nil, err } // 検証エラーを収集 checkErrors = append(checkErrors, checker.CheckErrors()...) // 中断のフラグが立っていればループを抜ける if checker.HasStop() { break } } return checkErrors, nil }
モックを使い、検証の詳細は意識せずに自身の実装範囲のみを検証するテストコードになっています。
コード(記載量が多いので折りたたんでます)
// mockChecker は Checker インターフェースのモック実装 type mockChecker struct { checkError error checkErrors []CheckError hasStop bool } func (m *mockChecker) EnableStopOnError() Checker { return m } func (m *mockChecker) Check() error { return m.checkError } func (m *mockChecker) HasStop() bool { return m.hasStop } func (m *mockChecker) CheckErrors() []CheckError { return m.checkErrors } // 検証の実行処理に対するテストコード func TestChainChecker_Execute(t *testing.T) { t.Parallel() tests := []struct { name string setupCheckers func() []Checker wantCheckErrors []CheckError wantErr error }{ { name: "正常系:全てのチェックが成功し、エラーがない場合", setupCheckers: func() []Checker { return []Checker{ &mockChecker{}, &mockChecker{}, &mockChecker{}, } }, wantCheckErrors: []CheckError{}, }, { name: "正常系:複数のチェッカーでチェックエラーが発生した場合", setupCheckers: func() []Checker { return []Checker{ &mockChecker{ checkErrors: []CheckError{ {RowNumber: 2, DocumentID: "doc-id-1", Message: "error from checker 1"}, }, }, &mockChecker{ checkErrors: []CheckError{ {RowNumber: 3, DocumentID: "doc-id-2", Message: "error from checker 2"}, {RowNumber: 4, DocumentID: "doc-id-3", Message: "another error from checker 2"}, }, }, &mockChecker{ checkErrors: []CheckError{ {RowNumber: 5, DocumentID: "doc-id-4", Message: "error from checker 3"}, }, }, } }, wantCheckErrors: []CheckError{ {RowNumber: 2, DocumentID: "doc-id-1", Message: "error from checker 1"}, {RowNumber: 3, DocumentID: "doc-id-2", Message: "error from checker 2"}, {RowNumber: 4, DocumentID: "doc-id-3", Message: "another error from checker 2"}, {RowNumber: 5, DocumentID: "doc-id-4", Message: "error from checker 3"}, }, }, // 以降のケースは省略 } for _, tt := range tests { t.Run(tt.name, func(t *testing.T) { t.Parallel() require := require.New(t) assert := assert.New(t) cc := &chainChecker{ logger: slog.Default(), checkers: tt.setupCheckers(), } checkErrors, err := cc.Execute() if tt.wantErr != nil { require.Error(err) assert.Equal(tt.wantErr.Error(), err.Error()) return } require.NoError(err) assert.Equal(tt.wantCheckErrors, checkErrors) }) } }
検証ロジックの詳細
ここではファイルの検証と重複の検証のサンプルを記載しますが、他の検証についても Checker interface を実装する形で同じ構成となります。
Check メソッドの中身はそれぞれの検証ロジックが実装されます。
他の検証ロジックの詳細を意識する必要はありません。
コード(記載量が多いので折りたたみ可能にしています)
type validatorFile struct { param CheckerParam hasStopOnError bool checkErrors []CheckError } func NewValidatorFile(param CheckerParam) Checker { return &validatorFile{ param: param, } } // 実行されるとエラーがあった際に処理を中断するためのフラグが立てられる func (v *validatorFile) EnableStopOnError() Checker { v.hasStopOnError = true return v } // 検証ロジック func (v *validatorFile) Check() error { // ファイルサイズが0の場合 if len(v.param.CSVData()) == 0 { v.addCheckError("ファイルが空です") } // ファイルサイズが上限を超えている場合 if len(v.param.CSVData()) > MaxFileSize { v.addCheckError("ファイルサイズが上限を超えています") } return nil } func (v *validatorFile) HasStop() bool { return v.hasStopOnError && len(v.checkErrors) > 0 } func (v *validatorFile) CheckErrors() []CheckError { return v.checkErrors } func (v *validatorFile) addCheckError(message string) { v.checkErrors = append(v.checkErrors, CheckError{Message: message}) }
type validatorDuplication struct { param CheckerParam hasStopOnError bool checkErrors []CheckError } func NewValidatorDuplication(param CheckerParam) Checker { return &validatorDuplication{ param: param, } } func (v *validatorDuplication) EnableStopOnError() Checker { v.hasStopOnError = true return v } func (v *validatorDuplication) Check() error { rows, err := v.param.CSVDataRows() if err != nil { return err } // キー: 書類ID, 値: 行番号 のマップを作成 foundDocIDs := make(map[string]int) for _, row := range rows { // 書類ID列が存在しない または 空の場合はスキップ if row.IsEmptyAt(ColIndexDocumentID) { continue } docID := row.ValueAt(ColIndexDocumentID) rowNum, exists := foundDocIDs[docID] // 重複していない場合はマップに登録して次へ if !exists { foundDocIDs[docID] = row.Number continue } // 以降、重複している場合のエラー追加 ce := CheckError{ RowNumber: row.Number, DocumentID: docID, DocumentTitle: row.ValueAt(ColIndexDocumentTitle), Message: fmt.Sprintf("書類IDが%d行目と重複しています", rowNum), } v.addCheckError(ce) } return nil } func (v *validatorDuplication) HasStop() bool { return v.hasStopOnError && len(v.checkErrors) > 0 } func (v *validatorDuplication) CheckErrors() []CheckError { return v.checkErrors } func (v *validatorDuplication) addCheckError(checkError CheckError) { v.checkErrors = append(v.checkErrors, checkError) }
入力値の取得をモックにして、自身の検証処理だけを意識したテストコードになっています。
コード(記載量が多いので折りたたんでます)
// mockCheckerParam は CheckerParam インターフェースのモック実装 type mockCheckerParam struct { CheckerParam csvData []byte } func (m *mockCheckerParam) CSVData() []byte { return m.csvData } func TestValidatorFile_Check(t *testing.T) { t.Parallel() validCSVData := []byte("書類ID,書類名,書類項目1\n1,test,value\n") tests := []struct { name string csvData []byte wantErrorCount int wantErrors []string }{ { name: "正常なCSVファイル", csvData: validCSVData, wantErrorCount: 0, wantErrors: []string{}, }, { name: "空ファイル", csvData: []byte{}, wantErrorCount: 1, wantErrors: []string{"ファイルが空です"}, }, { name: "ファイルサイズ上限超過", csvData: make([]byte, MaxFileSize+1), wantErrorCount: 1, wantErrors: []string{"ファイルサイズが上限を超えています"}, }, } for _, tt := range tests { t.Run(tt.name, func(t *testing.T) { t.Parallel() assert := assert.New(t) require := require.New(t) mockParam := &mockCheckerParam{ csvData: tt.csvData, } validator := NewValidatorFile(mockParam) err := validator.Check() require.NoError(err) checkErrors := validator.CheckErrors() require.Len(checkErrors, tt.wantErrorCount) for i, wantMsg := range tt.wantErrors { assert.Equal(wantMsg, checkErrors[i].Message) } }) } }
データ形式に依存するロジックのカプセル化
CSV の行番号とそれに対応する値を構造体にラップして、データ形式に依存するロジックをカプセル化することで扱いやすくしています。
コード(記載量が多いので折りたたみ可能にしています)
// 行番号と CSV の行データをラップする構造体 type CSVRow struct { Number int Values []string } // ヘッダーや無効な行を除いても問題ないように行番号を保持する形でラップする func NewCSVRows(rows [][]string) []CSVRow { csvRows := make([]CSVRow, len(rows)) for i, row := range rows { csvRows[i] = CSVRow{ Number: displayRowNumber(i), Values: row, } } return csvRows } func (cr CSVRow) Length() int { return len(cr.Values) } func (cr CSVRow) ExistsAt(colIndex ColIndex) bool { index := int(colIndex) return index >= 0 && index < len(cr.Values) } func (cr CSVRow) NotExistsAt(colIndex ColIndex) bool { return !cr.ExistsAt(colIndex) } func (cr CSVRow) IsPresentAt(colIndex ColIndex) bool { index := int(colIndex) if index < 0 || index >= len(cr.Values) { return false } return cr.Values[index] != "" } func (cr CSVRow) IsEmptyAt(colIndex ColIndex) bool { return !cr.IsPresentAt(colIndex) } func (cr CSVRow) ValueAt(colIndex ColIndex) string { index := int(colIndex) if index < 0 || index >= len(cr.Values) { return "" } return strings.TrimSpace(cr.Values[index]) }
さらなる改善の余地
リファクタリングの規模が大きくなりすぎる
リファクタリングによるレビュー負荷やリグレッションのリスクを軽減したい場合もあります。 そういった場合はメインロジックと検証ロジックの依存を弱めるだけにして、それが済んでからそれ以降を改善するなどの段階的な対応も検討する価値があります。
処理時間が長くなりやすい
現状だと検証ロジックごとにループを回すケースが多く、 CSV の行数や検証の種類が増えると処理時間が大きく伸びていく可能性があります。
その場合は入力値の管理に sync パッケージを適用することでスレッドセーフにして、そのうえで検証ロジックを goroutine で並行実行する選択肢もあります。
入力データの管理が膨らみやすい
入力データの管理で検証ロジック全体をカバーする場合、扱う値や制御が膨らみやすいです。 その場合、利用範囲や扱うデータ形式で処理を切り出すなど、さらなるリファクタリングを行ったほうが良い可能性もあります。
最後に
最初から仕様をシンプルにできると一番良いのですが、ある程度の複雑性が避けられない場合もあります。 複雑になった場合は責務の分離と依存の逆転によって適切に抽象化してリファクタリングしてみてください。 本記事の例が、その際のヒントになれば幸いです。